

About 1,500 Days and Counting . . . (Part II)


In my last post I started on an assessment of what happened during the era of COCK (Crazily Overexaggerated Covid Kookiness). I am beginning to realise this may have been unwise, as there’s so much astonishing cockishness to cover. This was originally meant to be a kind of covid 4-year anniversary (single) post, but I might still be writing this series this time next year. I’d best brush up on my Roman numerals because I’ve forgotten how to write 4,327 using them.
Part I was about establishing the “Big Picture”, the overall narrative that shaped everything. I want to emphasize, as I have many times before, that none of COCK could have happened without the assumption of some super-deadly new disease that had emerged that threatened the entire world.
It was the deliberate stoking of fear, preying on our instinctive fears of an invisible killer pathogen, that generated the environment in which the COCK grew.
I’m sorry, it’s terribly bad schoolboy humour, I know. But if I expressed my true contempt for the people who foisted this disastrous mess on us, it’d be much worse and a lot cruder. I’ve previously described this state of madness as having a Corona Boner, which adequately describes the state of irrationality. Most men have experienced the temporary loss of rationality when little William starts to get interested1.
This (wholly unwarranted and false) assumption of ‘unprecedented’ severity lit the fuse. Everything else follows from this, along with the myth of asymptomatic transmission (AT). Even AT is of no consequence without the severity assumption - can you imagine being manipulated into staying at home for days on end if you had an asymptomatic cold?
For those of us who remember what work was like before we could get frequent 2 week breaks for having tested positive for the CoronaDoom™ can you imagine phoning your boss and saying you need 2 weeks off because you have asymptomatic flu?
For some reason, we decided to start thinking of this new(ish) virus in a totally different way. It became like the Napoleon Corona-apart of viruses. Unique, deadly, and dangerous, that could only be defeated with a significant extraordinary effort.
When we were finally allowed out to mingle a bit we found that not everything was being driven by the dread totalitarian hands of our governments. Many families took it upon themselves to require a negative covid test as a condition of acceptance at any gathering.
Children were prevented from seeing their grandparents in case they killed them. I can only hope these buffoons did not tell their kids the reason. Can you imagine the guilt you could create? Gramps died 2 weeks after your visit, Johnny. You probably killed him.
It was a time of sickness, but mostly it was people being sick in the head as a result of the incessant propaganda.

How did the hysteria get such a hold of so many of us? One of the big factors on which we can lay the blame was the whole testing program. This served a dual purpose. It could, purportedly, identify those infected and it also served as a brilliant psyops tool to further promote the fear and sense of severity.
My university required regular testing at the time in order to attend campus. There was a testing centre set up on campus. It was like visiting the set of a movie. A warren of corridors had been constructed so that we didn’t accidentally come into contact with people (despite having to wait in a queue along with, erm, other people). When you finally navigated this maze you’d be met by someone swathed in plastic. The message was clear; you are a danger, you could infect someone.
If you tested negative the mandated rinky-dinky little phone app would turn green (in a couple of days) and you could enter campus for the next couple of weeks. It’s all rather stupid isn’t it? If that day I’d gone to a bookstore and picked up a book that hadn’t been quarantined, I might have been infected and be spreading my deadly germiness for the next 2 weeks all over campus!
Fucking morons.
Calm down, Rigger, calm down. Grit your teeth and at least try to maintain some veneer of professionalism.
The disease was of such (alleged) severity and consequence that we all needed to be subjected to this program of regular testing.
But what did all this foolish frippery actually achieve? More importantly, why did we think it was a good idea in the first place?
Medical Testing (the math bit)
As I’ve noted before, the human body only produces a fairly limited range of symptoms. Many conditions have an overlapping set of symptoms and not all symptoms are present in every case. Doctors have to play a sort of detective role trying to figure out what might be causing the presented symptoms.
One of the things they can do is to test for whatever thing they suspect might be the problem, if such a test is available.
It’s a useful tool that is part of the diagnostic armoury.
For covid, we ditched all of that. A positive test became synonymous with a diagnosis, even when symptoms were not present.
Medical testing must be judiciously applied - and the reason for that is buried in the mathematics of probability.
The central idea we must grasp is that of conditional probability. Mathematically this is usually written something like P(X|Y) which is read as “the probability of X given Y”.
What this means is that we’re distinguishing between the following 2 things
P(X) : the probability of X happening
P(X| extra information) : the probability of X with some new information
I’m going to use a racially-charged example, just for the hell of it.
Let’s suppose we looked at white men and black men. Some of those white men have a gun, some of those black men have a gun.
There are 2 variables here
Colour : which can take the values black or white (colour = B, or colour = W)
Armed : which can take the values gun or ‘no gun’ (armed = G, or armed = NG)
The way to think about probability for these kinds of situations is to think of it as a selection process. You could have everybody put into a room. You now select one of these men entirely at random2.
There are now some probability questions we can ask :
What’s the probability that we pick a white man?
What’s the probability that we pick someone with a gun?
Now, suppose we separate the group by colour so that white men go into one room and black men into another. We now focus on the white room. This is extra ‘information’ we’re given about our selection; we’re only going to be picking from those in the white room.
What, now, is the probability of picking someone with a gun when making this selection at random?
We have extra information. We know that they are white and so the probability here is P(A=G | C=W). This is read as:
The probability we’ve picked someone who has a gun given that we’re only picking from white people.
But we can do this ‘the other way round’. We swap things so that we have P(C|A) instead of P(A|C). What does this mean?
In terms of the example above we’d be asking the probability question P(C=W | A=G) this time, instead.
This is the probability that we pick a white person, given they have a gun. It’s a different scenario. Before, we split everyone in terms of colour. This time, with the ‘swap’, we’re doing a different split. This time round we separate the group into those who have a gun and those who do not. The room we focus on is now the gun room.
You can see how this ‘swap’ profoundly affects our whole picture of what’s going on.
Entirely different scenarios represented by two entirely different ways of splitting the initial population up.
The following graphic illustrates the significance of these two different ways of splitting up the initial population where we have a group composed of 18 black and 18 white men
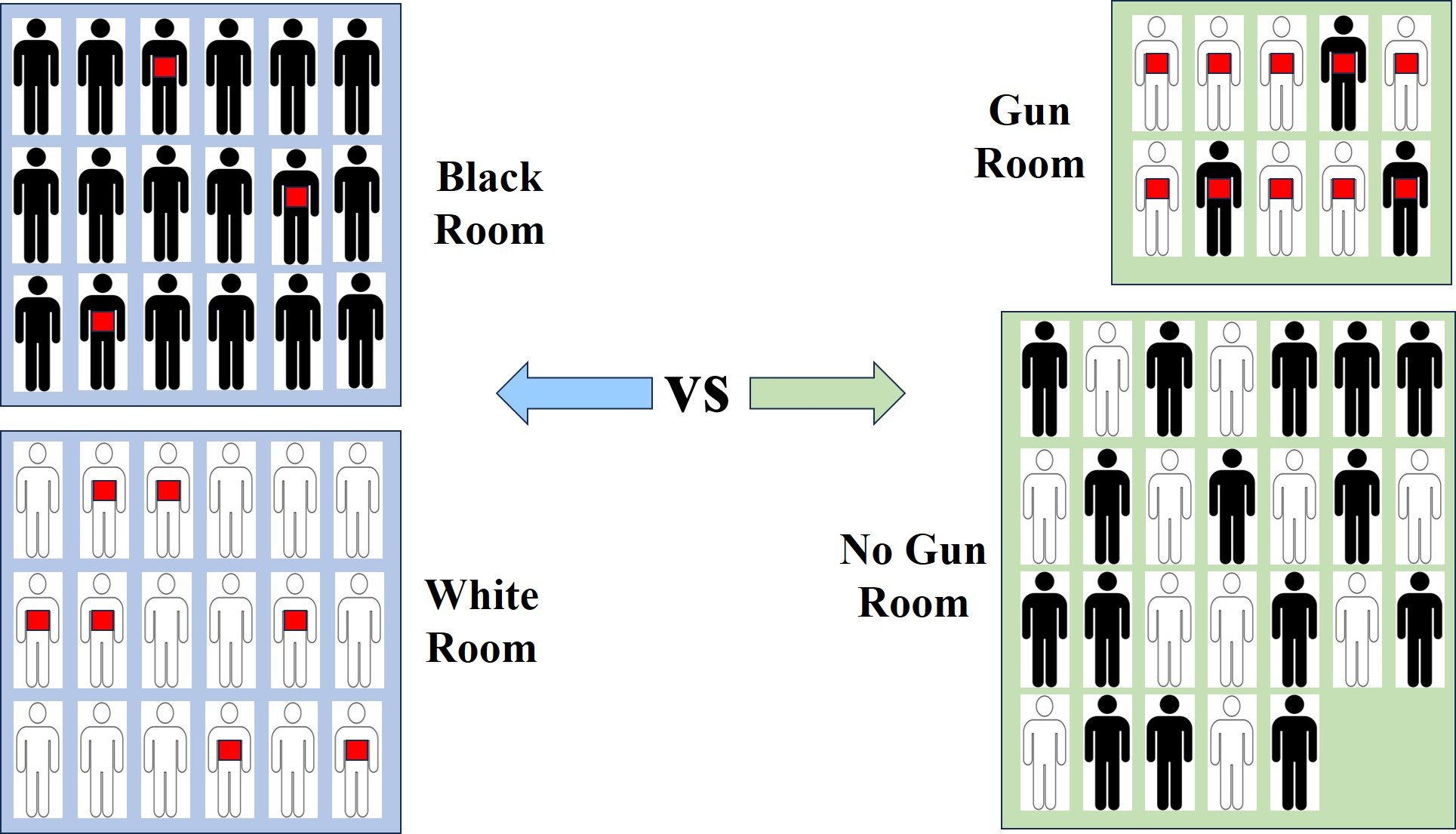
In terms of our example probability questions above we can easily see from this graphic that
P(A=G | C=W) = 7/18 [checking the numbers from the blue rooms]
P(C=W | A=G) = 7/10 [checking the numbers from the green rooms]
This is precisely the same situation we have when it comes to medical testing.
And the difference between the two ‘scenarios’ is hugely important.
When we characterize the accuracy of a medical test we’re interested in two things; (a) does it confirm the disease and (b) how likely is it to give a wrong result?
When we, as a patient, get tested we’re interested in a different question. We want to know whether we have the disease or not.
At first glance it seems like these are, more or less, the same questions, but it’s actually exactly the same as the various room-split scenarios we have above.
In the medical version of this we also have 2 variables :
T : test result, with values 1 (yes) or 0 (no)
D : disease, with values 1 (yes) or 0 (no)
A medical test is characterized by the following 2 probabilities
P(T=1 | D = 1)
P(T=0 | D = 0)
These get called fancy technical names (sensitivity and specificity, respectively).
In this case what we do is to split the population by the disease variable into 2 rooms; those with the disease and those without (at least conceptually). We conduct the test. A perfect test would give the result 1 for all those in the disease room and the result 0 for all those in the non-disease room.
A test which has 98% specificity would get the right answer (which is 0) for those in the non-disease room 98% of the time.
But, as a patient, that’s not what we’re really interested in. What the patient is interested in is the following
Aw shucks, Doc, the test came back positive. Do I really have the disease?
In other words, the patient wants to know the answer to the following probability question (the ‘room’ split here is into those with a positive test result and those without)
P(D=1 | T = 1) = ???????
Notice the swap here. The patient is interested in the blue room split, say, whereas the test is characterized by the green room split.
The math question is, then, how are these two different ways of splitting things related?
I won’t go through the algebra. It’s fairly straightforward with a knowledge of a few probability properties, but the answer is the following.
where S is the test sensitivity, F is the test specificity, and pi is the prevalence of the disease in the (sample) population. The prevalence is the probability of the disease in the chosen sample.
It’s not immediately obvious unless you’re used to analysing math formulae like this, but there’s something interesting that happens when the disease prevalence becomes low.
Re-writing the above formula in a way that seems more complicated, we have
which looks like
If AB can get large, which it can do when the prevalence is small, then the probability on the left will be small.
In other words, even though you might have a reliable and accurate test (although not 100% perfect), even a positive result can imply a low probability of having the disease.
So you can have a highly accurate and reliable test at the individual ‘test’ level, but one that has little predictive value when applied to the population as a whole.
As Prof Fenton has recently emphasized, this effect of low prevalence swamps everything, even when we have highly reliable and accurate tests (determined by high values of sensitivity and specificity).

How are we to understand this well-known result? It’s something basic that is covered in medical degrees. Every doctor should know about this. Yet, somehow, all of this got “conveniently” forgotten about during the COCK era when we started testing people willy-nilly.
Making Sense of the Squiggles
My favourite way of explaining this result is to cast everything in terms of a binary communication channel. Here we imagine a sender (Alice) and a receiver (Bob). Alice is able to send a ‘1’ or a ‘0’ on the channel, and at the other end Bob will receive either a ‘1’ or a ‘0’.
Now, let’s suppose that Alice sends ‘0’ almost all the time, but every so often, say about 1 in 1,000 transmissions she decides to send ‘1’, just to mix things up a bit.
In our disease terms, this ‘1’ represents the disease, and 1 in 1,000 is the prevalence.
Let’s now suppose that the channel is quite good, but not perfect. Every now and then it introduces an error. This means that sometimes the symbol gets flipped by the time it gets to Bob.
Let’s imagine that this happens with, on average, 1 out of every 100 transmitted symbols.
You can think of the transmission over the channel as a medical ‘test’ that gets it right 99% of the time.
So, roughly speaking, if Alice sends 1,000 symbols to Bob one of those symbols will be ‘1’.
But the channel turns the 999 ‘0’ symbols that are sent into a ‘1’ with a 1% probability.
So, at the other end, Bob will receive about 11 symbols that read as a ‘1’.
But Alice only sent 1 such symbol!
This means that most of those ‘1’ symbols that arrive at Bob are errors. Bob, receiving a ‘1’ symbol, can only give it a 10% probability (roughly) of actually having come from a ‘1’ that Alice sent.
This is exactly what’s happening with the medical test; the errors on the channel are characterized by formulae3 that use terms that are mathematically identical to the sensitivity and the specificity and the probability with which Alice sends the ‘1’ symbol is the prevalence.
Even if Alice gets more bored and decides to send a ‘1’ symbol every 100 transmissions, on average, you can see that Bob won’t be able to do any better than guessing at whether the ‘1’ he receives has come from a genuine case, or is an error on the channel.
It’s this comparison of the ‘prevalence’ with the error rate that is important.
Medical Malpractice
This mass testing of everyone, symptomatic or otherwise, propelled the whole testing saga into farce. Most of the positive results, in times of low prevalence, were coming from individual false positives. The ‘population’ false positive rate can be very different from the ‘test’ false positive rate.
It was completely bonkers.
We should have, of course, restricted our sample to only those who possessed symptoms and were strongly suspected of suffering from the tested condition. This automatically means that you’re testing a sample where the prevalence is likely to be high and you avoid this low-prevalence trap. This is what doctors used to do, before the almighty COCK of despair came along.
But no, driven crazy by COCK, we decided to ditch established medical practice.
Damn it. I’m just going to say it
Fucking morons.
What Was The Point Anyway?
Test and Trace might be a useful thing to do right at the very initial stages of an outbreak where you can rapidly identify those who might be infectiousness. This works well for something like Ebola, say, where it’s quite difficult to transmit the disease anyway.
But when you’ve got a highly contagious respiratory virus and thousands of people have it or have already been exposed, you’re just wasting your time. It would be like doing Test and Trace for an outbreak of a cold.
Utterly pointless.
But it made a few million (or billion) quid for those tasked with implementing the farce. In terms of actually helping mitigate the transmission of the disease it did bugger all.
Armed with the green tick of joy on our smartphones, we could wave our smug asymptomatic faces at the door guards and waltz in to wherever.
Those unfortunate few, also asymptomatic, who weren’t so lucky had to stay at home. No going to market for those little piggies.
Once again, note the emphasis on asymptomatic transmission. If you had symptoms you’d be staying at home anyway (unless you were a complete dick). This Test and Trace thing was only to ‘catch’ those nasty, dirty, asymptomatic super-spreaders. Those evil, and mythical creatures who lived amongst us.
And Substack has gotten bored of me and told me this post is getting too long for email. So, time to give those electrons in the computer a rest and to hit the brandy again
In covid-speak we could describe this as thinking with our protein spike instead of our brains
I don’t want to get into the technicalities of what this actually means, but it turns out to be quite difficult to properly pin down
On a communication channel we characterize errors by the conditional probabilities P(1|0) and P(0|1) where the this is constructed as P(Bob receives | Alice sent). The equivalent to ‘sensitivity’ for the channel is just 1 - P(0|1) and for ‘specificity’ it’s just 1 - P(1|0)
You have a knack for ranting without going overboard into Hectoring. That's a compliment.
I was (via Die Fackel) looking at gonorrhea-numbers from Norway. They've jumped like a dolphin from 2022 to 2024. Why? Main reason is, STDs erupt in cycles when several high risk groups all at once spreads it around - swingers, BDSM-clubs, homosexuals, Pride-events and prostitution, all of it create a rather even background level of STDs, and once in a while, factors conspire to ensure several groups suffers outbreaks above the norm all at once. Other times, the same factors fail to kick in even to the average level, giving the impression of a drop.
Here's the funny bit: if you're a politician, a capitalist or a clerk in an organisation under the control of either or both, it's in your rational interest to utilise this according to the will of your bosses. And that's why you get alarums about disease or condition X rising rapidly, or measure Y being so very effective condition or disease Z drops rapidly.
The alternative is of course to try and use data to get a comprehensive picture of reality, but where's the profit in that when you can use models to create reality to your benefit?
It really is that easy: ever since the 1980s, rational self-interest (also called rational choice theory) has been the underlying guiding theory in the West, and the ontological measuring rod for ethics re: politics and capital.
Every little functionaire acts in their immediate self-interest before all other concerns. According to the theory, this yields the best results.
Reality speaks for itself as to why this theory is worth less than barnacle-droppings.
Thanks for re-familiarizing me with the mathematics behind false positives. I forgot about that, I was thinking of uncertainty also related to what actually was being tested and how fast they were spinning the test (I forget the official word for that). Brian Mowry implied that pcr's effectively tested for something, I don't know if you read it but here's the link, I'd love to know what you think.
https://unglossed.substack.com/p/statements-on-severe-efficacy
I think Alice and Bob worked better to make your point than the overly long gun scenario.